Guia do usuário¶
…or IDT’s list of opinionated howtos
Esta seção busca fornecer aos usuários da infraestrutura Apuana conhecimentos práticos, dicas e truques e comandos de exemplo.
Executando o seu código¶
Guia de comandos SLURM¶
Uso básico¶
A documentação do SLURM https://slurm.schedmd.com/documentation.html fornece informações extensas sobre os comandos disponíveis para consultar o status do cluster ou enviar trabalhos.
A seguir, são apresentados alguns exemplos básicos de como usar o SLURM.
Enviando trabalhos¶
Trabalho em lote¶
Para enviar um trabalho em lote, você precisa criar um script contendo o(s) comando(s) principal(is) que deseja executar nos recursos/nós alocados.
#!/bin/bash
#SBATCH --job-name=test
#SBATCH --output=job_output.txt
#SBATCH --error=job_error.txt
#SBATCH --ntasks=1
#SBATCH --time=10:00
#SBATCH --mem=100Gb
module load python/3.5
python my_script.py
Seu script de trabalho é então enviado para o SLURM com sbatch (ref.)
$ sbatch job_script
sbatch: Submitted batch job 4323674
O diretório de trabalho do trabalho será aquele onde você executou o comando sbatch.
Dica
As diretivas do Slurm podem ser especificadas na linha de comando juntamente
com sbatch ou dentro do script de trabalho com uma linha iniciada por #SBATCH.
Job interativo¶
Os gerenciadores de carga geralmente executam trabalhos em lote para evitar ter que monitorar
sua progressão e deixar o agendador executá-lo assim que os recursos estiverem disponíveis.
Se você quiser acessar um shell enquanto utiliza recursos do cluster, pode enviar um trabalho
interativo onde o executável principal é um shell com o comando srun/salloc.
salloc
Iniciar um trabalho interativo no primeiro nó disponível com os recursos padrão
definidos no SLURM (1 tarefa/1 CPU). O comando srun aceita os mesmos argumentos
que sbatch, com exceção do ambiente que não é passado.
Dica
Para passar seu ambiente atual para um trabalho interativo, adicione --preserve-env ao srun.
salloc também pode ser usado e é principalmente um invólucro em torno de srun se
fornecido sem mais informações, mas fornece mais flexibilidade se, por exemplo,
você quiser obter uma alocação em vários nós.
Argumentos de submissão de tarefas¶
Para selecionar com precisão os recursos para sua tarefa, vários argumentos estão disponíveis. Os mais importantes são:
Argumento |
Descrição |
|---|---|
-n, –ntasks=<number> |
O número de tarefas no seu script, geralmente é 1. |
-c, –cpus-per-task=<ncpus> |
O número de núcleos para cada tarefa. |
-t, –time=<time> |
Tempo solicitado para o seu trabalho. |
–mem=<size[units]> |
Memória solicitada para todas as tarefas do seu trabalho. |
–gres=<list> |
Selecione recursos genéricos, como GPUs, para o seu trabalho: |
Dica
Sempre considere solicitar a quantidade adequada de recursos para melhorar o agendamento do seu trabalho (trabalhos pequenos sempre são executados primeiro).
verificando job status¶
Para exibir os jobs atualmente na fila, use squeue e para obter apenas seus trabalhos digite squeue -u $USER
$ squeue -u $USER
JOBID USER NAME ST START_TIME TIME NODES CPUS TRES_PER_NMIN_MEM NODELIST (REASON) COMMENT
133 my_username myjob R 2019-03-28T18:33 0:50 1 2 N/A 7000M node1 (None) (null)
Nota
O número máximo de trabalhos que podem ser enviados ao sistema por usuário é 1000 (MaxSubmitJobs=1000) em qualquer momento da associação dada. Se este limite for atingido, novas solicitações de envio serão negadas até que os trabalhos existentes nesta associação sejam concluídos.
Removendo um job¶
Para cancelar o seu trabalho, simplesmente use scancel.
scancel 4323674
Particionamento¶
Como não temos muitas GPUs no cluster, os recursos devem ser compartilhados de forma justa.
A opção --partition=/-p do SLURM permite que você defina a prioridade necessária para um trabalho.
Cada trabalho atribuído com uma prioridade pode interromper trabalhos com prioridade mais baixa:
unkillable > main > long. Uma vez interrompido, seu trabalho é morto sem aviso prévio e é automaticamente
reenfileirado na mesma partição até que os recursos estejam disponíveis. (Para aproveitar um mecanismo de
interrupção diferente, consulte a documentação do SLURM).
Handling preemption)
Flag |
Max Resource Usage |
Max Time |
Note |
|---|---|---|---|
--partition=unkillable |
6 CPUs, mem=32G, 1 GPU |
2 days |
|
--partition=unkillable-cpu |
2 CPUs, mem=16G |
2 days |
CPU-only jobs |
--partition=short-unkillable |
24 CPUs, mem=128G, 4 GPUs |
3 hours (!) |
Large but short jobs |
--partition=main |
8 CPUs, mem=48G, 2 GPUs |
5 days |
|
--partition=main-cpu |
8 CPUs, mem=64G |
5 days |
CPU-only jobs |
--partition=long |
no limit of resources |
7 days |
|
--partition=long-cpu |
no limit of resources |
7 days |
CPU-only jobs |
Aviso
Historicamente, antes da introdução em 2022 de nós exclusivos para CPU
(por exemplo, a série “cn-f”), trabalhos apenas com CPU eram executados lado
a lado com trabalhos com GPU em nós de GPU. Para evitar que esses trabalhos
obstruíssem qualquer trabalho com GPU, eles sempre tinham a menor prioridade
e eram preemptíveis. Isso foi implementado automaticamente atribuindo-os a uma
das partições agora obsoletas cpu_jobs, cpu_jobs_low ou cpu_jobs_low-grace.
Não use mais esses nomes de partição. Prefira os nomes de partição *-cpu definidos acima.
Para fins de compatibilidade com versões anteriores, os nomes das partições legadas são traduzidos
para seu equivalente efetivo long-cpu, mas eventualmente serão removidos completamente.
Nota
Como conveniência, se você solicitar a partição unkillable, main ou long para um trabalho
apenas com CPU, a partição será traduzida automaticamente para seu equivalente -cpu.
Preocupações e soluções de portabilidade¶
Ao trabalhar em um projeto de software, é importante estar ciente de todo o software e bibliotecas nos quais o projeto depende e listá-los explicitamente e sob um sistema de controle de versão de tal forma que possam ser facilmente instalados e disponibilizados em diferentes sistemas. As vantagens são significativas:
Facilidade de instalação e execução no cluster
Facilidade de colaboração
Melhor reprodutibilidade
Para alcançar isso, tente sempre manter em mente os seguintes aspectos:
- Versões: Para cada dependência, certifique-se de ter algum registro da versão
específica que está usando durante o desenvolvimento. Dessa forma, no futuro, você poderá reproduzir o ambiente original que sabe ser compatível. De fato, quanto mais tempo passa, mais provável é que novas versões de alguma dependência tenham alterações quebradas. O comando pip freeze pode criar tal registro para dependências do Python.
- Isolamento: Idealmente, cada um de seus projetos de software deve estar isolado dos outros.
O que isso significa é que atualizar o ambiente do projeto A não deve atualizar o ambiente do projeto B. Dessa forma, você pode instalar e atualizar software e bibliotecas livremente para o primeiro, sem se preocupar em quebrar o segundo (o que você pode não perceber até semanas depois, na próxima vez em que trabalhar no projeto B!) O isolamento pode ser alcançado usando Python Virtual environments and containers.
Gerenciando seus ambientes¶
Ambientes virtuais¶
Um ambiente virtual em Python é um ambiente local e isolado no qual você pode instalar ou desinstalar pacotes do Python sem interferir no ambiente global (ou em outros ambientes virtuais). Ele geralmente fica em um diretório (a localização varia dependendo se você usa venv, conda ou poetry). Para usar um ambiente virtual, você precisa ativá-lo. Ativar um ambiente define essencialmente variáveis de ambiente em seu shell para que:
pythonaponta para a versão correta do Python para aquele ambiente (diferentes ambientes virtuais podem usar
diferentes versões do Python!)
pythonprocura pacotes no ambiente virtualpip installinstala pacotes no ambiente virtualQuaisquer comandos de shell instalados via
pip installestão disponíveis
Para executar experimentos dentro de um ambiente virtual, você pode simplesmente ativá-lo no script fornecido para sbatch.
Pip/Virtualenv¶
O Pip é o gerenciador de pacotes preferido para Python e cada cluster fornece diversas versões do Python por meio do módulo associado, que vem com o pip. Para instalar novos pacotes, você primeiro precisará criar um espaço pessoal para que eles possam ser armazenados. A solução preferida (assim como é nos clusters da Digital Research Alliance do Canadá) é usar ambientes virtuais.
Primeiro, carregue o módulo Python que você deseja usar: .. code-block:: console
module load python/3.8
Então, crie um ambiente virtual no seu diretório home:
python -m venv $HOME/<env>
onde <env> é o nome do seu ambiente. Finalmente, ative o ambiente:
source $HOME/<env>/bin/activate
Agora você pode instalar qualquer pacote Python que desejar usando o comando pip, por exemplo:
pytorch:
pip install torch torchvision
Or Tensorflow:
pip install tensorflow-gpu
Conda¶
Outra solução para Python é usar o conda.
Você pode carregar o módulo do conda com o seguinte comando:
module load miniforge3/2025.07
Para verificar a versão do conda instalada, use:
conda --version
Para criar um novo ambiente conda, use o seguinte comando:
conda create --n <env> python=<version> -y
Finalmente, para ativar o ambiente, use:
conda activate <env>
E para desativar o ambiente:
conda deactivate
Outras informações também podem ser encontradas em: https://docs.conda.io/en/latest/miniconda.html ou anaconda https://docs.anaconda.com
Usando módulos¶
Muito software, como Python e Conda, já está compilado e disponível no cluster por
meio do comando module e seus subcomandos. Em particular, se você deseja usar
o Python 3.7, basta fazer:
module load python/3.7
No uso de contêineres¶
Outra opção para criar código portátil é: Using containers.
- Containers são uma abordagem popular para implantar aplicativos, empacotando juntos muitas das dependências necessárias.
A ferramenta mais popular para isso é o Docker.
Compartilhando dados com ACLs¶
Os bits de permissão regulares são ferramentas extremamente limitadas: eles controlam o acesso por meio de apenas três conjuntos de bits - usuário proprietário, grupo proprietário e todos os outros. Portanto, o acesso é ou muito restrito (0700 permite acesso apenas ao usuário proprietário) ou muito amplo (770 dá todas as permissões para todos no mesmo grupo, e 777 para literalmente todos).
As ACLs (Listas de Controle de Acesso) são uma expansão dos bits de permissão que permitem um controle mais granular de acessos a um arquivo. Elas podem ser usadas para permitir que usuários específicos acessem arquivos e pastas, mesmo que as permissões padrão conservadoras os tenham negado esse acesso.
Como exemplo ilustrativo, para usar as ACLs para permitir que $USER (a si mesmo) compartilhe com $USER2 (outra pessoa) uma hierarquia de pastas “playground” no sistema de arquivos de rascunho do Apuana em um local
/network/scratch/${USER:0:1}/$USER/X/Y/Z/...
de maneira segura e que permita que ambos os usuários leiam, escrevam, executem, pesquisem e excluam os arquivos um do outro:
-d renders this permission a “default” / inheritable one)setfacl -Rdm user:${USER}:rwx /network/scratch/${USER:0:1}/$USER/X/Y/Z/
Nota
A importância de fazer este passo aparentemente redundante primeiro é que arquivos e pastas são sempre de propriedade de apenas uma pessoa, quase sempre o seu criador (o UID será do criador, o GID geralmente também). Se esse usuário não for você, você não terá acesso a esses arquivos a menos que a outra pessoa especificamente os dê a você - ou esses arquivos herdem uma ACL padrão que permita acesso total.
This Esta é a ACL padrão herdada que serve esse propósito.
-d renders this permission a “default” / inheritable one)setfacl -Rdm user:${USER2}:rwx /network/scratch/${USER:0:1}/$USER/X/Y/Z/
setfacl -Rm user:${USER2}:rwx /network/scratch/${USER:0:1}/$USER/X/Y/Z/
Nota
- O objetivo de conceder permissões primeiro para arquivos futuros e depois para arquivos
existentes é evitar uma condição de corrida em que, após o primeiro comando
setfacl, a outra pessoa possa criar arquivos aos quais o segundo comandosetfaclnão se aplica.
Non-recursive (!!!!)
- May also grant
:rxin unlikely event others listing your folders on the path is not troublesome or desirable.
- May also grant
setfacl -m user:${USER2}:x /network/scratch/${USER:0:1}/$USER/X/Y/
setfacl -m user:${USER2}:x /network/scratch/${USER:0:1}/$USER/X/
setfacl -m user:${USER2}:x /network/scratch/${USER:0:1}/$USER/
Nota
Para acessar um arquivo, todas as pastas desde o diretório raiz (/) até a pasta pai
em questão devem ser pesquisáveis (+x) pelo usuário em questão. Isso já é o caso
para todos os usuários em pastas como /, /network e /network/scratch, mas os usuários
devem conceder acesso explicitamente a alguns ou a todos os usuários, seja por meio de
permissões básicas ou adicionando ACLs, para pelo menos /network/scratch/${USER:0:1}/$USER, $HOME e subpastas.
Para permitir bruscamente que todos os usuários pesquisem uma pasta (pense duas vezes!), o seguinte comando pode ser usado:
chmod a+x /network/scratch/${USER:0:1}/$USER/
Nota
Para obter mais informações sobre
setfacle resolução de caminho/verificação de acesso, considere os seguintes comandos de visualização de documentação:
man setfaclman path_resolution
Visualizando e Verificando ACLs¶
getfacl /path/to/folder/or/file
1: # file: somedir/
2: # owner: lisa
3: # group: staff
4: # flags: -s-
5: user::rwx
6: user:joe:rwx #effective:r-x
7: group::rwx #effective:r-x
8: group:cool:r-x
9: mask::r-x
10: other::r-x
11: default:user::rwx
12: default:user:joe:rwx #effective:r-x
13: default:group::r-x
14: default:mask::r-x
15: default:other::---
Nota
man getfacl
Nós Múltiplos¶
Paralelismo de Dados¶
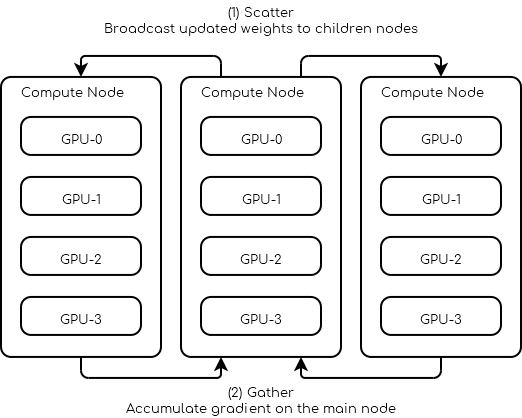
Solicite 3 nós com pelo menos 4 GPUs cada um.
#!/bin/bash
# Number of Nodes
#SBATCH --nodes=3
# Number of tasks. 3 (1 per node)
#SBATCH --ntasks=3
# Number of GPU per node
#SBATCH --gres=gpu:4
#SBATCH --gpus-per-node=4
# 16 CPUs per node
#SBATCH --cpus-per-gpu=4
# 16Go per nodes (4Go per GPU)
#SBATCH --mem=16G
# we need all nodes to be ready at the same time
#SBATCH --wait-all-nodes=1
# Total resources:
# CPU: 16 * 3 = 48
# RAM: 16 * 3 = 48 Go
# GPU: 4 * 3 = 12
# Setup our rendez-vous point
RDV_ADDR=$(hostname)
WORLD_SIZE=$SLURM_JOB_NUM_NODES
# -----
srun -l torchrun \
--nproc_per_node=$SLURM_GPUS_PER_NODE\
--nnodes=$WORLD_SIZE\
--rdzv_id=$SLURM_JOB_ID\
--rdzv_backend=c10d\
--rdzv_endpoint=$RDV_ADDR\
training_script.py
Você pode encontrar abaixo um esboço de um script do PyTorch sobre como um treinador multi-nó pode ser elaborado.
import os
import torch.distributed as dist
class Trainer:
def __init__(self):
self.local_rank = None
self.chk_path = ...
self.model = ...
@property
def device_id(self):
return self.local_rank
def load_checkpoint(self, path):
self.chk_path = path
# ...
def should_checkpoint(self):
# Note: only one worker saves its weights
return self.global_rank == 0 and self.local_rank == 0
def save_checkpoint(self):
if self.chk_path is None:
return
# Save your states here
# Note: you should save the weights of self.model not ddp_model
# ...
def initialize(self):
self.global_rank = int(os.environ.get("RANK", -1))
self.local_rank = int(os.environ.get("LOCAL_RANK", -1))
assert self.global_rank >= 0, 'Global rank should be set (Only Rank 0 can save checkpoints)'
assert self.local_rank >= 0, 'Local rank should be set'
dist.init_process_group(backend="gloo|nccl")
def sync_weights(self, resuming=False):
if resuming:
# in the case of resuming all workers need to load the same checkpoint
self.load_checkpoint()
# Wait for everybody to finish loading the checkpoint
dist.barrier()
return
# Make sure all workers have the same initial weights
# This makes the leader save his weights
if self.should_checkpoint():
self.save_checkpoint()
# All workers wait for the leader to finish
dist.barrier()
# All followers load the leader's weights
if not self.should_checkpoint():
self.load_checkpoint()
# Leader waits for the follower to load the weights
dist.barrier()
def dataloader(self, dataset, batch_size):
train_sampler = ElasticDistributedSampler(dataset)
train_loader = DataLoader(
dataset,
batch_size=batch_size,
num_workers=4,
pin_memory=True,
sampler=train_sampler,
)
return train_loader
def train_step(self):
# Your batch processing step here
# ...
pass
def train(self, dataset, batch_size):
self.sync_weights()
ddp_model = torch.nn.parallel.DistributedDataParallel(
self.model,
device_ids=[self.device_id],
output_device=self.device_id
)
loader = self.dataloader(dataset, batch_size)
for epoch in range(100):
for batch in iter(loader):
self.train_step(batch)
if self.should_checkpoint():
self.save_checkpoint()
def main():
trainer = Trainer()
trainer.load_checkpoint(path)
tainer.initialize()
trainer.train(dataset, batch_size)
Nota
“Para contornar o GIL (Bloqueio Global do Interpretador) do Python, o PyTorch cria um processo para cada GPU. No exemplo acima, isso significa que pelo menos 12 processos são criados, pelo menos 4 em cada nó.”