O que é um cluster de computadores?¶
Um cluster de computadores https://pt.wikipedia.org/wiki/Cluster é um conjunto de computadores conectados de forma solta ou estreita que trabalham juntos para que, em muitos aspectos, possam ser vistos como um único sistema.
Partes de um cluster de computação¶
Para fornecer capacidades de computação de alto desempenho, clusters podem combinar centenas a milhares de computadores, chamados de nós, que são todos interconectados por uma rede de comunicação de alto desempenho. A maioria dos nós são projetados para cálculos de alto desempenho, mas clusters também podem usar nós especializados para oferecer sistemas de arquivos paralelos, bancos de dados, nós de login e até mesmo a funcionalidade de agendamento do cluster, conforme ilustrado na imagem abaixo.
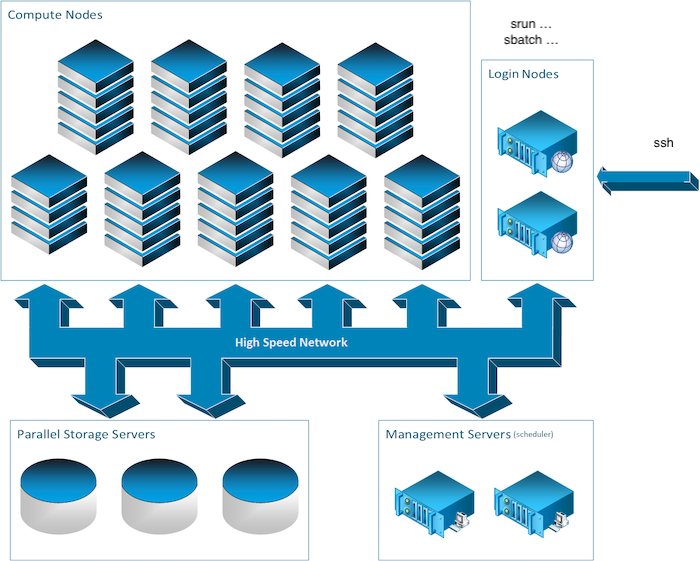
Vamos revisar os diferentes tipos de nós que você pode encontrar em um cluster típico.
Os nós de login¶
Para executar processos de computação em um cluster, você primeiro deve se conectar a um cluster e isso é feito através de um nó de login. Esses chamados nós de login são o ponto de entrada para a maioria dos clusters.
Outro ponto de entrada para alguns clusters, como o cluster Mila, é a interface web JupyterHub, mas leremos sobre isso mais tarde. Por enquanto, voltemos ao assunto desta seção: os nós de login. Para se conectar a eles, você normalmente usaria uma conexão de shell remoto. A ferramenta mais comum para fazer isso é o SSH. Você ouvirá e lerá muito sobre essa ferramenta. Imagine-a como um cabo de extensão muito longo (e um pouco mágico) que conecta o computador que você está usando agora, como seu laptop, ao terminal shell de um computador remoto. Você pode já saber o que é um terminal shell se já usou a linha de comando.
Os nós de computação¶
No campo da inteligência artificial, geralmente você estará à procura de GPUs. Na maioria dos clusters, os nós de computação são aqueles com capacidade de GPU.
Embora haja um paradigma geral de tendência para uma configuração homogênea para nós, isso nem sempre é possível no campo da inteligência artificial, já que o hardware evolui rapidamente e é complementado por novos hardware, e assim por diante. Portanto, você frequentemente lerá sobre classes de nós computacionais. Alguns deles podem ter modelos de GPU diferentes ou até mesmo nenhuma GPU.
Os nós de armazenamento¶
Alguns computadores em um cluster funcionam apenas para armazenar e servir arquivos. Embora o nome desses computadores possa ser importante para alguns, como usuário, você só se preocupa com o caminho dos dados. Mais sobre isso na seção Processamento de dados.
Nós diferentes para usos diferentes¶
É importante notar aqui a diferença nos usos pretendidos entre os nós de computação e os nós de login. Enquanto os nós de computação são destinados a computação pesada, os nós de login não são.
Os nós de login, no entanto, são usados por todos que usam o cluster e deve-se tomar cuidado para não sobrecarregá-los. Consequentemente, apenas processos muito curtos e leves devem ser executados nesses nós, caso contrário, o cluster pode se tornar inacessível. Em outras palavras, por favor, abstenha-se de executar processos longos ou de computação intensiva em nós de login, pois isso afeta todos os outros usuários. Em alguns casos, você também descobrirá que fazer isso pode lhe causar problemas.
UNIX¶
Todos os clusters geralmente são executados em distribuições GNU/Linux. Portanto, é geralmente exigido um conhecimento mínimo de GNU/Linux e BASH para usá-los.
Consulte o seguinte tutorial https://docs.alliancecan.ca/wiki/Linux_introduction para obter um guia básico sobre como começar com o Linux.
O gerenciador de carga de trabalho¶
Em um cluster, os usuários não têm acesso direto aos nós de computação, mas se conectam a um nó de login e adicionam trabalhos à fila do gerenciador de carga de trabalho. Sempre que houver recursos disponíveis para executar esses trabalhos, eles serão alocados para um nó de computação e executados, o que pode acontecer imediatamente ou após uma espera de vários dias.
Um trabalho consiste em uma série de etapas que serão executadas uma após a outra. Isso é feito para que você possa agendar uma sequência de processos que podem usar os resultados das etapas anteriores sem ter que interagir manualmente com o escalonador.
Cada etapa pode ter qualquer número de tarefas, que são grupos de processos que podem ser agendados independentemente no cluster, mas podem ser executados em paralelo se houver recursos disponíveis. A distinção entre etapas e tarefas é que várias tarefas, se fizerem parte da mesma etapa, não podem depender dos resultados de outras tarefas porque não há garantias sobre a ordem em que serão executadas.
Finalmente, cada grupo de processos é a unidade básica agendada no cluster. Ele consiste em um conjunto de processos (ou threads) que podem ser executados em vários recursos (CPU, GPU, RAM, …) e são agendados juntos como uma unidade em uma ou mais máquinas.
Cada um desses conceitos é adequado para um uso específico. Para treinamento com várias GPUs em cargas de trabalho de inteligência artificial, você usaria uma tarefa por GPU para paralelismo de dados ou um grupo de processos se estiver fazendo paralelismo de modelo. A otimização de hiperparâmetros pode ser feita usando uma combinação de tarefas e etapas, mas provavelmente é melhor deixá-la para um framework fora do escopo do gerenciador de carga de trabalho.
Se tudo isso parece complicado, você deve saber que todas essas coisas não precisam ser usadas sempre. É perfeitamente aceitável enviar trabalhos com uma única etapa, uma única tarefa e um único processo.
Os recursos disponíveis no cluster não são infinitos e é o trabalho do gerenciador de carga alocá-los. Sempre que uma solicitação de trabalho é feita e não há recursos suficientes disponíveis para iniciar imediatamente, ele será colocado na fila.
Uma vez que um trabalho está na fila, ele permanecerá lá até que outro trabalho termine e, em seguida, o gerenciador de carga tentará usar os recursos liberados com trabalhos da fila. A ordem exata em que os trabalhos serão iniciados não é fixa, pois depende das políticas locais que podem levar em conta a prioridade do usuário, o tempo desde que o trabalho foi solicitado, a quantidade de recursos solicitados e possivelmente outras coisas. Deve haver uma ferramenta que acompanha o gerenciador em que você pode ver o status dos trabalhos em fila e por que eles permanecem na fila.
O gerenciador de carga irá dividir o cluster em partições de acordo com a configuração definida pelos administradores. Uma partição é um conjunto de máquinas geralmente reservadas para um propósito específico. Um exemplo pode ser máquinas somente com CPU para pré-processamento configuradas como uma partição separada. É possível que várias partições compartilhem recursos.
Sempre haverá pelo menos uma partição que é a partição padrão na qual os trabalhos sem solicitação específica serão executados. Outras partições podem ser solicitadas, mas podem ser restritas a um grupo de usuários, dependendo da política.
As partições são úteis do ponto de vista de política para garantir o uso eficiente dos recursos do cluster e evitar o uso excessivo de um tipo de recurso que possa bloquear o uso de outro. Elas também são úteis para clusters heterogêneos, onde diferentes hardwares são misturados e nem todos os softwares são compatíveis com todos eles (por exemplo, CPUs x86 e POWER).
Para garantir uma distribuição justa dos recursos de computação para todos, o gerenciador de carga estabelece limites na quantidade de recursos que um único usuário pode usar de uma só vez. Esses limites podem ser limites rígidos que impedem a execução de trabalhos quando você ultrapassa ou limites flexíveis que permitirão que você execute trabalhos, mas apenas até que outro trabalho precise dos recursos.
A política do administrador determinará quais são os limites exatos para um cluster ou usuário específico e se eles são limites rígidos ou flexíveis.
A forma como os limites flexíveis são aplicados é por meio de preempção, o que significa que quando outro trabalho com prioridade mais alta precisa dos recursos que seu trabalho está usando, seu trabalho receberá um sinal de que precisa salvar seu estado e sair. Será dado um certo tempo para isso (o período de graça, que pode ser de 0s) e depois ele será encerrado à força se ainda estiver em execução.
Dependendo do gerenciador de carga em uso e da configuração do cluster, um trabalho que seja preemptionado dessa forma pode ser automaticamente reagendado para ter a chance de terminar ou pode caber ao trabalho reagendar-se.
O outro limite que pode ser encontrado é com um trabalho que ultrapassa seus limites declarados. Ao agendar um trabalho, você declara quanto de recursos ele precisará (RAM, CPUs, GPUs, …). Alguns desses recursos podem ter valores padrão e não serem definidos explicitamente. Para determinados tipos de dispositivos, como GPUs, o acesso a unidades acima do limite do seu trabalho fica indisponível. Para outros, como RAM, o uso é monitorado e seu trabalho será encerrado se exceder o limite. Isso torna importante garantir que você estime com precisão o uso de recursos.
Comandos de cliente Slurm estão disponíveis nos nós de login para que você possa enviar trabalhos para o controlador principal e adicioná-los à fila. Existem dois tipos de trabalhos: trabalhos em lote (batch) e trabalhos interativos (interactive).
Processamento de dados¶
Para processar grandes quantidades de dados comuns para o aprendizado profundo, seja para pré-processamento de conjuntos de dados ou treinamento, existem várias técnicas. Cada uma tem usos e limitações típicas
Paralelismo de dados¶
A primeira técnica é chamada de paralelismo de dados (também conhecida como paralelismo de tarefas na ciência da computação formal). Você simplesmente executa muitos processos, cada um lidando com uma parte dos dados que você deseja processar. Isso é de longe a técnica mais fácil de usar e deve ser favorecida sempre que possível. Um exemplo comum disso é a otimização de hiperparâmetros.
Para cálculos realmente pequenos, o tempo para configurar vários processos pode ser maior do que o tempo de processamento e levar a desperdício. Isso pode ser resolvido agrupando alguns dos processos juntos, fazendo o processamento sequencial de subpartições dos dados.
Para os sistemas de cluster, também não é recomendável lançar milhares de trabalhos e mesmo que cada trabalho fosse executado por um período razoável de tempo (vários minutos no mínimo), seria melhor formar grupos maiores até que a quantidade de trabalhos seja no máximo algumas centenas.
Finalmente, outra coisa a ter em mente é que a largura de banda de transferência é limitada entre os sistemas de arquivos (consulte Preocupações com o sistema de arquivos`) e os nós de computação e se você executar muitos trabalhos usando muitos dados de uma só vez, eles podem não ser mais rápidos porque passarão seu tempo esperando pelos dados chegarem.
Paralelismo de modelo¶
A segunda técnica é chamada de paralelismo de modelo (que não tem um único equivalente na ciência da computação formal). É usada principalmente quando uma única instância de um modelo não cabe em um recurso de computaçã o (como a memória da GPU sendo muito pequena para todos os parâmetros).
Nesse caso, o modelo é dividido em suas partes constituintes, cada uma processada independentemente e seus resultados intermediários comunicados entre si para chegar a um resultado final.
Isso é geralmente mais difícil, mas necessário para trabalhar com modelos maiores e mais poderosos como o GPT.
Preocupações com a comunicação¶
A principal diferença dessas duas abordagens é a necessidade de comunicação entre os múltiplos processos. Alguns métodos comuns de treinamento, como o descida de gradiente estocástica, ficam em algum lugar entre os dois, pois requerem alguma comunicação, mas não muita. A maioria das pessoas classifica-o como paralelismo de dados, já que fica mais próximo desse fim.
Em geral, para tarefas de paralelismo de dados ou tarefas que se comunicam com pouca frequência, não faz muita diferença onde os processos estão, porque a largura de banda e a latência de comunicação não terão muito impacto no tempo necessário para concluir o trabalho. As tarefas individuais podem geralmente ser agendadas independentemente.
Por outro lado, para o paralelismo de modelo, você precisa prestar mais atenção a onde estão suas tarefas. Nesse caso, geralmente é necessário usar as instalações do gerenciador de carga de trabalho para agrupar as tarefas de modo que estejam na mesma máquina ou em máquinas que estejam intimamente ligadas para garantir uma comunicação ideal. A melhor alocação depende da arquitetura específica do cluster disponível e das tecnologias que ele suporta (como InfiniBand, RDMA, NVLink ou outras).
Preocupações com o sistema de arquivos¶
Ao trabalhar em um cluster, você geralmente encontrará vários sistemas de arquivos diferentes. Normalmente, haverá nomes como “home”, “scratch”, “datasets”, “projects”, “tmp”.
A razão de ter diferentes sistemas de arquivos disponíveis em vez de um único gigante é fornecer para diferentes casos de uso. Por exemplo, o sistema de arquivos “datasets” seria otimizado para leituras rápidas, mas teria desempenho lento de escrita. Isso ocorre porque os conjuntos de dados geralmente são escritos uma vez e, em seguida, lidos com muita frequência para treinamento.
O conjunto de sistemas de arquivos fornecido pelo cluster que você está usando deve ser detalhado na documentação desse cluster e os nomes podem diferir dos acima. Você deve prestar atenção ao caso de uso recomendado na documentação e usar o sistema de arquivos apropriado para o trabalho apropriado. Existem casos em que um trabalho rodou centenas de vezes mais devagar porque tentou usar um sistema de arquivos que não era adequado para o trabalho.
Uma última coisa a prestar atenção é a política de retenção de dados para os sistemas de arquivos. Isso tem dois subpontos: por quanto tempo os dados são mantidos e se há backups.
Alguns sistemas de arquivos terão um limite de tempo para manter seus arquivos. Tipicamente, o limite é algum número de dias (como 90 dias), mas pode ser “enquanto o trabalho estiver sendo executado” para alguns.
Quanto aos backups, alguns sistemas de arquivos não terão um limite para os dados, mas também não terão backups. Para estes, é importante manter uma cópia de quaisquer dados cruciais em outro lugar. Os dados não serão excluídos intencionalmente, mas o sistema de arquivos pode falhar e perder todos ou parte de seus dados. Se você tiver algum dado que é crucial para um artigo ou para a sua tese, mantenha uma cópia adicional em outro lugar.
Software no cluster¶
Esta seção tem como objetivo conscientizar sobre os problemas que se pode encontrar ao tentar executar um software em diferentes computadores e como isso é tratado em clusters de computação típicos.
Em relação ao desenvolvimento em Python, recomendamos o uso de ambientes virtuais para instalar pacotes Python em isolamento.
Módulos de software do cluster¶
Os módulos são pequenos arquivos que modificam suas variáveis de ambiente para apontar para versões específicas de vários softwares e bibliotecas. Por exemplo, um módulo pode fornecer o comando “python” para apontar para o Python 3.7, outro pode ativar a versão 11.0 do CUDA, outro pode fornecer o pacote “torch” e assim por diante.
Para obter mais informações, consulte O comando module.
Contêineres¶
Os contêineres são uma forma especial de isolamento de software e suas dependências. Um contêiner é essencialmente uma máquina virtual leve: ele encapsula um sistema de arquivos virtual para uma instalação completa do sistema operacional, bem como uma rede e ambiente de execução separados.
Por exemplo, você pode criar um contêiner Ubuntu no qual instala vários pacotes usando “apt”, modifica configurações como faria como usuário root, e assim por diante, mas sem interferir na sua instalação principal. Uma vez construído, um contêiner pode ser executado em qualquer sistema compatível.
Para obter mais informações, consulte Usando contêineres.
Ambientes virtuais Python¶
Um ambiente virtual em Python é um ambiente local e isolado no qual você pode instalar ou desinstalar pacotes Python sem interferir no ambiente global (ou em outros ambientes virtuais). Para usar um ambiente virtual, primeiro você deve ativá-lo.
Para obter mais informações, consulte Ambientes virtuais.